
- Write With AI in Your Brand’s Voice with GrowthBar - April 21, 2023
- How Long Should a Blog Post Be? [2025] - April 14, 2023
- 13+ Best ChatGPT Prompts for SEOs [2025] - April 14, 2023
Ended soon
You know when you use Google to search for a service, or find information? And once the page loads there is always one website at the very top.
Sites in position 1 in the Google search engine results page (SERP) get 25% of all clicks. So needless to say, it’s important to follow SEO best practices to try and maximize your site’s position in the SERP.
But do you know how Google even finds your site in the first place?
The answer is Google’s crawlers. Google’s crawlers are like little digital robots that visit Web sites and collect information about those sites.
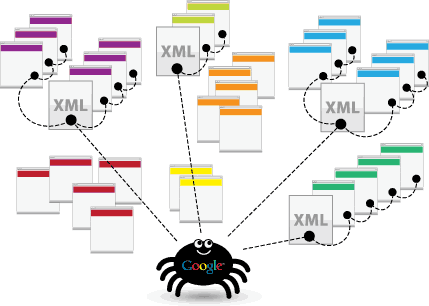
Then, Google indexes all of that information and uses it to improve its search algorithm. When someone types a query into Google, the search algorithm looks through all of the indexed information to find the best results for the person’s query.
And that’s how Google is able to bring you the best results when you search for something on the internet!
Table of Contents
What is a Google Crawler?
A Google Crawler is also known as a “robot” or “spider,” (get it, because they crawl) and they go from website to website on the hunt for new information to store in their databases. There are 15 kinds of crawlers that are used by Google but the most important one is Googlebot.

While Google is powerful it can’t do everything, each time a new web page is created Google doesn’t know about it until that page has been crawled.
Google uses the Googlebot to constantly gain the latest information to store in its database.
Also read: How to Write an Article that will Rank on Google in 6 Steps
Google Indexing vs Google Crawling
Indexing only happens after the website has been crawled by GoogleBot. When it is crawled, it is scanned, and the information scanned from that site or page is stored in the Google index. The index will categorize and rank the pages accordingly in the search results.
Why are Google Crawlers Important?
So why is all this important?
Well, let’s say you run a business and have a website. You want your website to be as close to the top as possible. If your website doesn’t get crawled and scanned it won’t load on the search page. Without any internet presence, you won’t be able to reach your audience or consumers. Crawling and indexing make it slightly easier for websites to get some attention.
How a Google Crawler Works
So, you know what it is but how does it work? While Google is powerful it can’t do everything, each time a new web page is created Google doesn’t know about it until that page has been crawled. Google uses the Googlebot to constantly gain added information to store in its database.
Once that web page is crawled or scanned. The page is rendered and given an HTML, CSS, JavaScript, and third-party code, all of which are needed for the Googlebot to index and rank websites. Googlebot, the biggest crawler, is able to see and render all the webpages and websites with Chromium.
The Chromium is always updating so that it can remain stable and perform its job accurately. This is available to everyone and can also be used for testing out new features and making new browsers.
How to Make Your Site Easier to Crawl
Now that we know what we’re working with, let’s work on making your website easy to be crawled. Here are some tips and tricks to make your website a crawler magnet and rise to the top on the search results page.
Internal Links
Internal links can be your best friend for crawling. Your site may have already been crawled by Google in the past but recently you may have added more pages. If the crawler already knows your website, it will only focus on the main pages. Remember, Google is not alerted any time a new page is made, it crawls to find those pages. Using internal links on main pages guides the crawler where it needs to go. The best place for these internal links is your homepage, it is the page that receives the most traffic and where the crawler will scan first.
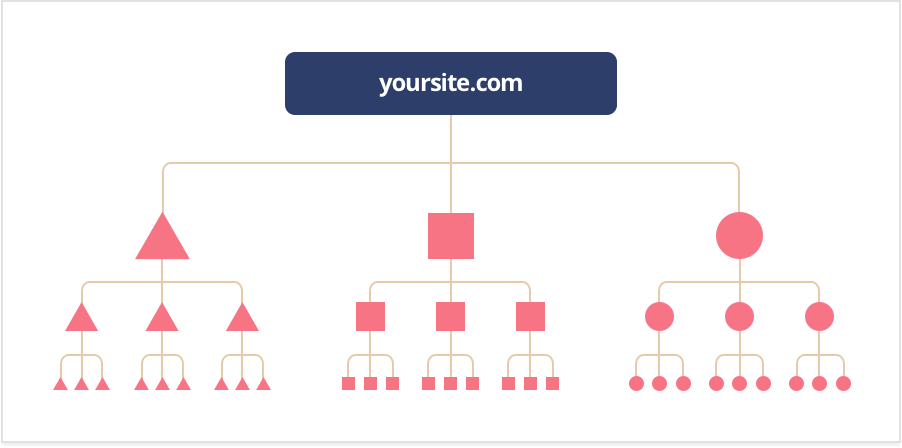
Backlinks
Backlinks are another great way to get your site crawled. This method can be used to “promote” your website to the crawler. Linking to a more popular website will boost your chances of being discovered by the crawler.
Images
Images can be crawled, in fact, there is a specific crawler just for images. This crawler is known as Googlebot Image, and it collects images for the database.
Sitemaps
There is a way to tell Google what pages you want them to crawl more directly. You can submit a sitemap with a detailed list of the pages that you want to be crawled by Google. Use WebSite Auditor to build a site map with their sitemap generator. Make it, name it. And download it to your computer to send it to Google, or you can publish it.
Click Depth
Click Depth shows you how much work a crawler would have to do to reach and scan your page. You never want the crawler to have to do too much work, you want your page or website to be as crawler friendly as possible. It should take about three clicks or less, the more it takes the more it slows down the crawler.
A good structure should allow you to add new pages without influencing your click depth. The crawler should still be able to reach these pages easily as well.
FYI: A good rule of thumb is to make sure you can navigate from a page on your site to any other page on your site with no more than 3 clicks. This ensures Google can find and index all of your pages efficiently. Plus, it’s great for user experience.
Indexing Instructions
There are instructions that Google follows when crawling and ideation pages. Robots.txt, noindex tag, robots meta tag, and X-Robots-Tag. Don’t worry, we’ll break this down for you.
Robots.txt. Is a root directory file that withholds certain pages and content from Google. When the crawler is scanning a page, it will be looking at this for information. If the crawler cannot find this information, it will cease its crawling and the page will not be a part of the search results.
Noindex tag prevent all types of crawlers from being able to scan and index a page.
Robots meta tag, can help control the way a page is supposed to be indexed and loaded for web surfers in the search results.
X-Robots-Tag, is a part of the HTTP header and will help control the behavior of the crawler. It oversees how the entire page is indexed. You can block images and videos on a page using this method. You are also able to target crawler types individually, but only if it’s specified. If the type of crawler is not specified, then the instructions will be for all Google crawlers.
URL Structure
You may have heard this one before but make sure you have a user-friendly URL. A URL that is easy, one that both your consumers and algorithms will love. Try to keep your URL as short and sweet as possible. If you have a long URL, it can be confusing not only to the human eye but to the Google bot as well.
The more confused the Googlebot, the more it will exhaust its crawling resources and that is definitely not what you want.
Common Issues (and Solutions) with Google Crawling
So, you have a page but it’s not performing the way you want it to. This could be because the crawler is having difficulties trying to scan and index your site. Here are a few common issues that people have come across with Google Crawling.
1. Google isn’t crawling your website
Make sure you are checking to see if your page or site is crawl friendly. That means having a good URL, incorporating the internal and backlinks if needed, or taking the time to create a sitemap to show Googlebot where to crawl. Also, keep in mind that it may take Google some time to crawl and index your website because it has to come find you!
2. You’ve been removed from Google’s index
Google will remove a website if it feels the need to, whether by law, relevancy or for not following the guidelines in place. Use the WebSite Auditor for click depth, tags, and anything that could be blocking the crawler from your page. Once you have done that you can submit your website to Google for reconsideration.
3. You have duplicate content
Duplicate content is a page that has similar content to another page or multiple URLS linking to one page.
In the case of having pages with similar content, which could also mean that you have a desktop and mobile version of one page. However, the most common example of duplicate content on a number of pages.
These can both be avoided and fixed with a canonical URL, or URL that serves as a representative for these duplicate pages. Google will only show the page that they believe has the most useful content on it and label it canonical. This is the page that will be crawled instead of the duplicates.
To avoid this, consider rewriting the text on these pages so that they aren’t confused as duplicates.
4. There are rendering issues
If you’re having rendering issues make sure your coding isn’t too big. Your coding needs to be as clean as possible so that the crawler can render everything properly. If the crawler cannot render the page, it will be considered empty.
Google Crawler FAQs
How long does it take for Google to crawl a website?
It normally takes Google anywhere from days to weeks to crawl. You can monitor crawling using the Index Status Report or the URL inspection tool. Remember, Google is not notified whenever a new website or page is made, it has to crawl and find it.
FYI: More popular sites are crawled faster. Brand new sites will usually require weeks to crawl, whereas reputable sites like NY Times, Wall Street Journal, and Wikipedia are crawled multiple times per day.
What is the Google Crawler algorithm?
The Google Crawler Algorithm is based on how crawler friendly your site is. This includes keywords, URLs, content and information, coding, and much more. It is up to you to provide Google with the best content and guidance so that it can find your page and start crawling.
Are all pages available for crawling?
This is a good question. The short answer is no. Some pages are not able to be crawled and indexed because they are password protected, were specifically excluded from the index instructions, or don’t have any links on their pages.
When will my website appear in Google search?
This will always vary depending on how long it takes for your website to be crawled and indexed. This could only take couple of days or as long as a few weeks.
What other web crawlers are there?
Yes! There are tons of web crawlers outside of Google’s fifteen. Here are a few for reference:
- There is BingBot used by the search engine Bing.
- SlurpBot, used by Yahoo! This web crawler is a mix between Yahoo! and Bing, because Bing primarily powers Yahoo!.
- ExaBot is the most popular search engine and crawler in France.
- AppleBot is used by the major tech Apple for spotlight search and Siri suggestions.
- Facebook, believe it or not, uses links to send content to other profiles and can only crawl if provided a link.
Optimize Your Site for Google Crawling
Now that you understand the basics of Google Crawling and how it works, use it to your advantage! Get your website indexed properly and climb to the top of the search result homepage. It’s free and completely at your disposal.


